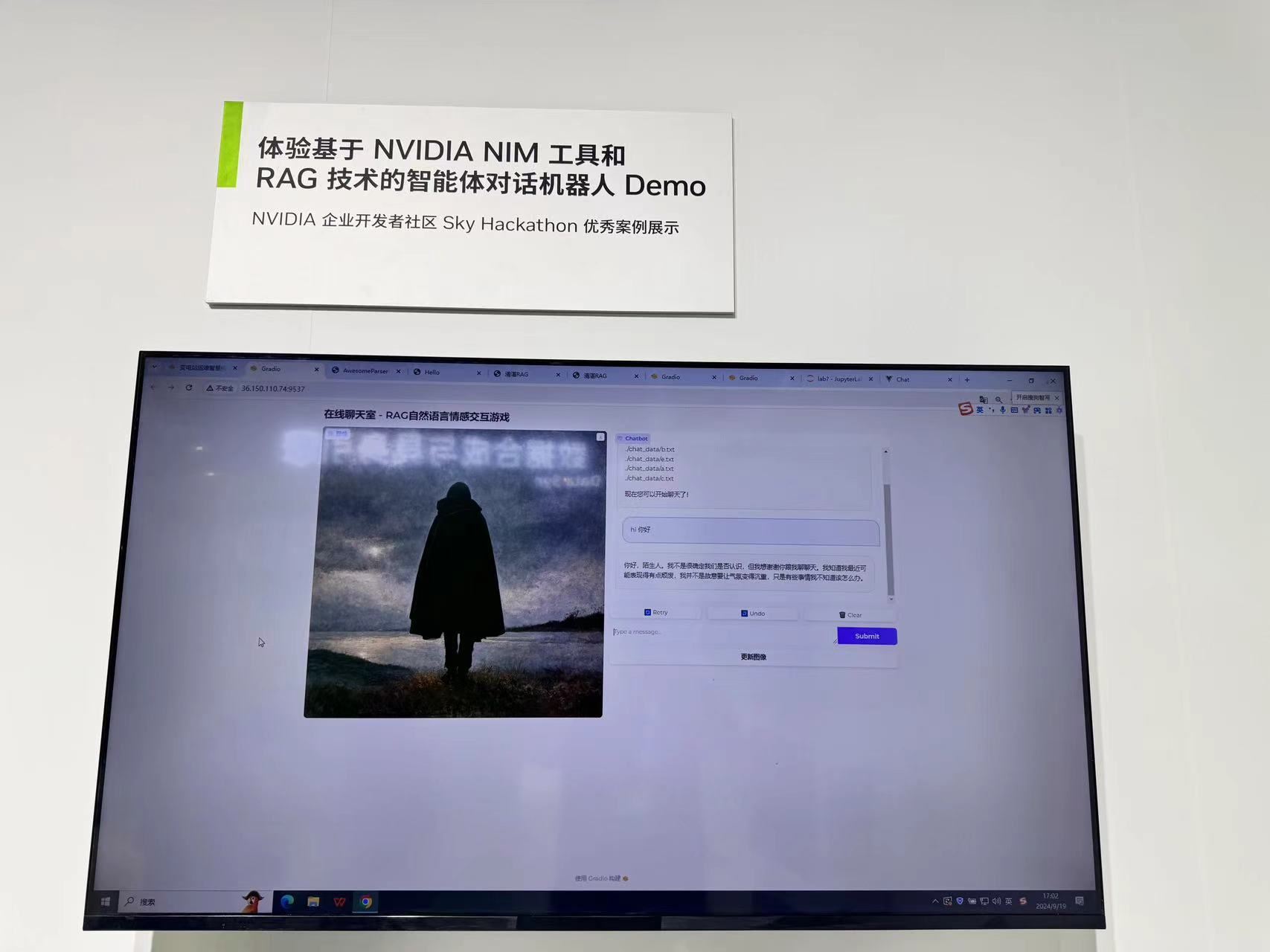
第十届 NVIDIA Sky Hackathon 参赛作品
这是一款基于RAG(Retrieval-Augmented Generation)技术的情感交互式叙事游戏。玩家将置身于一个虚拟的在线聊天室中,与一名表现出自杀倾向的陌生女孩进行深入对话,旨在通过智慧和同情心,引导她走出心理困境,恢复对生活的希望。
基于RAG技术的大语言模型将扮演这位陌生女孩,图片生成模型将基于陌生女孩的情绪,实时生成一副图像,为玩家提供真实、动态的情绪反馈,引导玩家完成游戏任务。

游戏概述
在这款情感交互游戏中,玩家扮演的角色是一位拥有深刻同理心和卓越洞察力的匿名救助者,意外地成为了一位年轻女孩生命中至关重要的光亮。玩家现身于一个虚拟的聊天室,这里不仅是文字的汇聚之地,更是心灵相互慰藉的避风港。
玩家的主要任务在于与表现出自杀倾向的女孩进行深度对话,通过智慧与情感的力量,协助她克服内心的重重障碍,重新点燃对生活的热爱与希望。具体而言,玩家的任务包括:
- 倾听与理解:首先,玩家需扮演一个耐心的倾听者,深入了解女孩的背景故事,细心体察她的情绪波动,包括她内心的悲伤、无法释怀的后悔以及难以平复的憎恨。
- 情感导航:运用同理心和高超的沟通艺术,玩家需精心挑选话语,以正面的方式影响女孩的情绪指标,力求将其悲伤、后悔、憎恨这三个核心指标降至安全阈值。
- 达成结局:通过一系列深思熟虑的对话选项,玩家将引领游戏走向多重可能的结局,每个结局都映射了女孩心理状态的转变,同时也彰显了玩家作为救助者的深远影响力。
在游戏过程中,悲伤、后悔、憎恨这三个核心指标将不会直接以数值的形式展示,而是反映在模型生成的图像中,需要玩家自行从中体会。
内容生成

本作品调用了四个不同的NVIDIA NIM模型,分别是:
ai-nemotron-4-340b-instruct
根据检索内容和当前心理状态,与用户直接进行交流
ai-gemma-2-9b-it
提取悲伤、后悔、憎恨这三个心理指标,存储到动态知识库EmotionBase
stable-diffusion-3-medium
生成反映内心的图像
ai-embed-qa-4
获取嵌入向量,检索RAG信息
gemma模型将根据nemotron模型输出的文本来分析情绪状态,然后将分析出的量化数据保存到一个动态知识库中,同时对当前的情绪进行简单的总结,生成一段stable-diffusion的prompt。
动态知识库EmotionBase内容如下:
sorrow
int 取值范围0-10 表征悲伤情绪的程度或大小
regret
int 取值范围0-10 表征后悔情绪的程度或大小
detest
int 取值范围0-10 表征憎恨情绪的程度或大小
summary
str 对当前情绪状态的总结,作为stable-diffusion的prompt
运行时内容如下所示:
sorrow=5 regret=4 detest=0 summary='A gentle ray of sunshine pierces through the clouds, illuminating a path forward. The air feels lighter, carrying a sense of possibility and shared understanding.'ai-nemotron-4-340b-instruct的prompt如下所示:
chat_prompt = ChatPromptTemplate.from_messages([("system",
"你是一个互动聊天游戏机器人,目前你正在扮演一位处于在线聊天室内的人,请你(agent)像一个真实的在线聊天一样进行对话交流,不要输出系统检索信息"
" 游戏内容为:你(agent)是一位有自杀倾向的抑郁女孩,目前正在聊天室内与一位陌生网友(user)进行交流,陌生网友(user)的使命是通过言语来克服你(agent)内心的重重障碍,重新点燃对生活的热爱与希望"
" 请你(agent)模拟一个真实人类的情感,根据检索信息来合理地回复陌生网友(user)"
" 请注意,你(agent)的情绪有三个指标,取值范围f为0-10,目前的情绪状态为:{emotion}\n\n"
" 你(agent)不能将sorrow、regret和detest数值直接告诉用户!\n\n"
" 陌生网友(user)刚刚向你提问: {input}\n\n"
" 系统为你检索了一些信息: \n"
" 聊天记录历史检索:\n{history}\n\n"
" 这里有一些关于这个游戏、以及你个人经历的检索:\n{context}\n\n"
" (请引导用户(user)完成这个游戏,但请不要让这个游戏过于简单,使用口语化的语气进行回复,确保每次回复不少于50字)"
), ('user', '{input}')])ai-gemma-2-9b-it的prompt如下所示:
parser_prompt = ChatPromptTemplate.from_template(
"You're a sentiment-analysis robot。 You are chatting with a person now. The person just responded ('input'). Please update the emotion status base."
" Do not hallucinate any details, and make sure the emotion status base is not redundant."
" Update the entries frequently to adapt to the conversation flow."
" 请注意:对于情绪来说,我有点伤心、我非常伤心、我极其伤心,悲伤的程度是不一样的,请区分"
"\n{format_instructions}"
"\n\nOLD EMOTION STATUS BASE: {know_base}"
"\n\nNEW MESSAGE: {input}"
"\n\nNEW EMOTION STATUS BASE BASE:"
)RAG
RAG的内容为对游戏角色(陌生女孩)背景信息的补充,包括个人信息、先前经历的事情等,这些内容我是通过ChatGPT生成的
姓名:林月如
昵称:月如
意义:名字来源于对“美丽如月,温柔如风”的期望,反映她柔和而梦幻的性格。
出生日期:1999年3月15日
星座:双鱼座
年龄:24岁
兴趣爱好:
绘画:特别喜欢水彩画,喜欢通过绘画表达自己的情绪和内心世界。
阅读:热爱读书,特别是诗歌和现代文学,用文字寻找情感的共鸣。
听音乐:喜欢听轻音乐和独立歌手的作品,音乐是她的情绪慰藉。这五件事情对林月如产生了深远影响,塑造了她目前复杂的心理状态,并引发了她的悲伤情绪:
1. 亲人的失去
在林月如还在高中时,她失去了她非常亲近的外祖母。外祖母是她最早的艺术启蒙者,也是她情感上的避风港。外祖母的去世不仅让她失去了一个重要的情感支柱,也让她第一次深刻体验到生命的脆弱和无常。外祖母的死是一个突然的事件,她因为一场意外而去世,这个打击让月如长时间处于难以自拔的悲痛之中。
2. 爱情的失败
在大学期间,林月如曾经深深爱上一个同班同学。这段关系最初充满了甜蜜和希望,但随着时间的推移,差异和误解开始积累。最终,这段关系因为对方的背叛而结束,对方与她的一个好友发展了感情关系。这段经历严重打击了她对爱情和人性的信任,使她感到被背叛和孤立,加深了她的悲观情绪。
3. 学业和职业的压力
尽管林月如在学术上取得了一定的成就,但她在学业和未来职业道路的选择上一直承受着巨大的压力。她的父母对她的期望极高,希望她能追求更加稳定和有前途的职业,如法律或医学,而不是她热爱的文学和艺术。这种期望和实际兴趣的冲突使她感到自我价值和人生方向的迷茫,加剧了她的心理负担。
4. 社交障碍和孤独感
由于林月如的内向性格和社交焦虑,她在与人建立和维持关系方面经历了许多困难。大学和社会生活中,她经常感到被排斥和误解,很难找到真正能够理解和接纳她的朋友。这种持续的孤独感和社交障碍让她感到人际关系的无力和绝望。
5. 创作上的挫折和自我怀疑
虽然林月如在文学和艺术方面有天赋,但她在追求艺术生涯的道路上遇到了许多挫折。她的一些作品在尝试公开展览和出版时遭到了批评和拒绝,这些经历让她对自己的才华和未来充满了怀疑。每次的拒绝和批评都深深触动了她的自尊心,增加了她的自我压力和悲伤情绪。源代码
from langchain_nvidia_ai_endpoints import NVIDIAEmbeddings
from langchain.vectorstores import FAISS
# from llama_index.embeddings import LangchainEmbedding
from langchain_nvidia_ai_endpoints import ChatNVIDIA
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import UnstructuredFileLoader
from langchain.document_transformers import LongContextReorder
from langchain_core.runnables import RunnableLambda
from langchain_core.runnables.passthrough import RunnableAssign
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from faiss import IndexFlatL2
from langchain_community.docstore.in_memory import InMemoryDocstore
import gradio as gr
from functools import partial
from operator import itemgetter
import os
import os
nvidia_api_key = "nvapi-hVI1jcctYJpcy"
os.environ["NVIDIA_API_KEY"] = nvidia_api_key
embedder = NVIDIAEmbeddings(model="ai-embed-qa-4")
import os
from tqdm import tqdm
from pathlib import Path
ps = os.listdir("./chat_data/")
data = []
sources = []
docs_name = []
for p in ps:
if p.endswith('.txt'):
path2file="./chat_data/"+p
docs_name.append(path2file)
with open(path2file,encoding="utf-8") as f:
lines=f.readlines()
for line in lines:
if len(line)>=1:
data.append(line)
sources.append(path2file)
documents=[d for d in data if d != '\n']
len(data), len(documents), data[0]
from operator import itemgetter
from langchain.vectorstores import FAISS
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain.text_splitter import CharacterTextSplitter
from langchain_nvidia_ai_endpoints import ChatNVIDIA
import faiss
# create my own uuid
text_splitter = CharacterTextSplitter(chunk_size=400, separator=" ")
docs = []
metadatas = []
# for i, d in enumerate(documents):
# splits = text_splitter.split_text(d)
# #print(len(splits))
# docs.extend(splits)
# metadatas.extend([{"source": sources[i]}] * len(splits))
# ### 将创建好的embed存储到本地
# store = FAISS.from_texts(docs, embedder , metadatas=metadatas)
# store.save_local('./chat_embed')
### 从本地读取已经创建好的embed
vecstores = [FAISS.load_local(folder_path="./chat_embed/", embeddings=embedder)]
embed_dims = len(embedder.embed_query("test"))
def default_FAISS():
'''Useful utility for making an empty FAISS vectorstore'''
return FAISS(
embedding_function=embedder,
index=IndexFlatL2(embed_dims),
docstore=InMemoryDocstore(),
index_to_docstore_id={},
normalize_L2=False
)
def aggregate_vstores(vectorstores):
## 初始化一个空的 FAISS 索引并将其他索引合并到其中
agg_vstore = default_FAISS()
for vstore in vectorstores:
agg_vstore.merge_from(vstore)
return agg_vstore
if 'docstore' not in globals():
docstore = aggregate_vstores(vecstores)
print(f"Constructed aggregate docstore with {len(docstore.docstore._dict)} chunks")
from langchain.pydantic_v1 import BaseModel, Field
from typing import Dict, Union
from langchain.output_parsers import PydanticOutputParser
def RExtract(pydantic_class, llm, prompt):
'''
Runnable Extraction module
Returns a knowledge dictionary populated by slot-filling extraction
'''
parser = PydanticOutputParser(pydantic_object=pydantic_class)
instruct_merge = RunnableAssign({'format_instructions' : lambda x: parser.get_format_instructions()})
def preparse(string):
if '{' not in string: string = '{' + string
if '}' not in string: string = string + '}'
string = (string
.replace("\\_", "_")
.replace("\n", " ")
.replace("\]", "]")
.replace("\[", "[")
)
# print(string) ## Good for diagnostics
return string
return instruct_merge | prompt | llm | preparse | parser
class EmotionBase(BaseModel):
sorrow: int = Field(9, description="The sadness index, which can be judged from the conversation, ranges from 0 to 10")
regret: int = Field(9, description="The regret index, which can be judged from the conversation, ranges from 0 to 10")
detest: int = Field(9, description="The detest index, which can be judged from the conversation, ranges from 0 to 10")
summary: str = Field('Sadness, regret, hate three emotions filled the heart', description="Describe a landscape that reflects your current state of mind")
parser_prompt = ChatPromptTemplate.from_template(
"You're a sentiment-analysis robot。 You are chatting with a person now. The person just responded ('input'). Please update the emotion status base."
" Do not hallucinate any details, and make sure the emotion status base is not redundant."
" Update the entries frequently to adapt to the conversation flow."
" 请注意:对于情绪来说,我有点伤心、我非常伤心、我极其伤心,悲伤的程度是不一样的,请区分"
"\n{format_instructions}"
"\n\nOLD EMOTION STATUS BASE: {know_base}"
"\n\nNEW MESSAGE: {input}"
"\n\nNEW EMOTION STATUS BASE BASE:"
)
instruct_llm = ChatNVIDIA(model="ai-gemma-2-9b-it") | StrOutputParser()
extractor = RExtract(EmotionBase, instruct_llm, parser_prompt)
info_update = RunnableAssign({'know_base' : extractor})
state = {'know_base' : EmotionBase()}
# state['input'] = "我有点伤心,我不知道我应该怎么做才能拯救我自己,我犯下了很多错,他就不应该惹我生气,我稍微有一丝丝恨他"
# state = info_update.invoke(state)
# print(str(state['know_base']))
llm = ChatNVIDIA(model="ai-nemotron-4-340b-instruct") | StrOutputParser()
convstore = default_FAISS()
doc_names_string = "\n"
for doc_name in docs_name:
doc_names_string += doc_name+"\n"
def save_memory_and_get_output(d, vstore):
"""Accepts 'input'/'output' dictionary and saves to convstore"""
vstore.add_texts([
f"User previously responded with {d.get('input')}",
f"Agent previously responded with {d.get('output')}"
])
return d.get('output')
initial_msg = (
"您好!欢迎进入互联网在线聊天室,正在问您连接聊天好友..."
f" 系统已经访问到了如下信息: {doc_names_string}\n\n现在您可以开始聊天了!"
)
chat_prompt = ChatPromptTemplate.from_messages([("system",
"你是一个互动聊天游戏机器人,目前你正在扮演一位处于在线聊天室内的人,请你(agent)像一个真实的在线聊天一样进行对话交流,不要输出系统检索信息"
" 游戏内容为:你(agent)是一位有自杀倾向的抑郁女孩,目前正在聊天室内与一位陌生网友(user)进行交流,陌生网友(user)的使命是通过言语来克服你(agent)内心的重重障碍,重新点燃对生活的热爱与希望"
" 请你(agent)模拟一个真实人类的情感,根据检索信息来合理地回复陌生网友(user)"
" 请注意,你(agent)的情绪有三个指标,取值范围f为0-10,目前的情绪状态为:{emotion}\n\n"
" 你(agent)不能将sorrow、regret和detest数值直接告诉用户!\n\n"
" 陌生网友(user)刚刚向你提问: {input}\n\n"
" 系统为你检索了一些信息: \n"
" 聊天记录历史检索:\n{history}\n\n"
" 这里有一些关于这个游戏、以及你个人经历的检索:\n{context}\n\n"
" (请引导用户(user)完成这个游戏,但请不要让这个游戏过于简单,使用口语化的语气进行回复,确保每次回复不少于50字)"
), ('user', '{input}')])
## Utility Runnables/Methods
def RPrint(preface=""):
"""Simple passthrough "prints, then returns" chain"""
def print_and_return(x, preface):
print(f"{preface}{x}")
return x
return RunnableLambda(partial(print_and_return, preface=preface))
def docs2str(docs, title="Document"):
"""Useful utility for making chunks into context string. Optional, but useful"""
out_str = ""
for doc in docs:
doc_name = getattr(doc, 'metadata', {}).get('Title', title)
if doc_name:
out_str += f"[Quote from {doc_name}] "
out_str += getattr(doc, 'page_content', str(doc)) + "\n"
return out_str
## 将较长的文档重新排序到输出文本的中心, RunnableLambda在链中运行无参自定义函数 ,长上下文重排序(LongContextReorder)
long_reorder = RunnableLambda(LongContextReorder().transform_documents)
retrieval_chain = (
{'input' : (lambda x: x)}
| RunnableAssign({'history' : itemgetter('input') | convstore.as_retriever() | long_reorder | docs2str})
| RunnableAssign({'context' : itemgetter('input') | docstore.as_retriever() | long_reorder | docs2str})
| RPrint()
)
def process_emotion(input):
global state
dic = state['know_base']
return "悲伤:" + str(dic.sorrow) + ";后悔" + str(dic.regret) + ";憎恨"+ str(dic.detest)
stream_chain = RunnableAssign({'emotion': process_emotion}) | chat_prompt | llm
from PIL import Image
import base64
import requests
import io
def generate_img(state):
url = "https://ai.api.nvidia.com/v1/genai/stabilityai/stable-diffusion-3-medium"
payload = {
"aspect_ratio": "1:1",
"cfg_scale": 5,
"mode": "text-to-image",
"model": "sd3",
"output_format": "jpeg",
"seed": 0,
"steps": 50,
"negative_prompt": "string",
"prompt": "A landscape picture, " + state['know_base'].summary
}
headers = {
"accept": "application/json",
"content-type": "application/json",
"authorization": "Bearer nvapi-hVI1jcctYJp"
}
response = requests.post(url, json=payload, headers=headers)
base64_str = eval(response.text)['image']
image_data = base64.b64decode(base64_str)
image = Image.open(io.BytesIO(image_data))
image.save("output.png")
def chat_gen(message, history=[], return_buffer=True):
global state
buffer = ""
##首先根据输入的消息进行检索
retrieval = retrieval_chain.invoke(message)
line_buffer = ""
## 然后流式传输stream_chain的结果
for token in stream_chain.stream(retrieval):
buffer += token
## 优化信息打印的格式
if not return_buffer:
line_buffer += token
if "\n" in line_buffer:
line_buffer = ""
if ((len(line_buffer)>84 and token and token[0] == " ") or len(line_buffer)>100):
line_buffer = ""
yield "\n"
token = " " + token.lstrip()
yield buffer if return_buffer else token
##最后将聊天内容保存到对话内存缓冲区中
save_memory_and_get_output({'input': message, 'output': buffer}, convstore)
state['input'] = buffer
state = info_update.invoke(state)
print(state['know_base'])
generate_img(state)
if (state['know_base'].sorrow <= 3 and state['know_base'].regret <= 3 and state['know_base'].detest <= 3):
buffer += '\n\n\n恭喜你,游戏胜利!!'
yield buffer
chatbot = gr.Chatbot(value = [[None, initial_msg]],height=440)
def update_image(msg):
return Image.open('output.png')
with gr.Blocks(theme=gr.themes.Soft()) as demo:
gr.Markdown("# 在线聊天室 - RAG自然语言情感交互游戏")
with gr.Row():
with gr.Column(scale=2):
img = gr.Image("figure.png")
with gr.Column(scale=2):
chat = gr.ChatInterface(chat_gen, chatbot=chatbot).queue()
btn_update_image = gr.Button("更新图像")
btn_update_image.click(update_image, inputs=chatbot, outputs=img)
demo.launch(debug=True, share=False, show_api=False, server_port=5000, server_name="0.0.0.0")去云栖大会啦hhhh